Корпусные приложения: N-gram Viewer, SketchEngine, AntConc
N-gram Viewer
N-грамма— последовательность изnслов. Последовательность из двух последовательных элементов часто называютбиграмма, последовательность из трёх элементов называетсятриграмма. Не менее четырёх и выше элементов обозначаются какN-грамма, N заменяется на количество последовательных элементов.
Использование данных при поиске и построении графиков ограничено N-граммами: для построения графика N-грамма должна встречаться в соответствующем корпусе не менее 40 раз.
Частотность – процент искомой единицы от числа соответствующих единиц (слово относительно всех слов, биграммы относительно всех биграмм и т.д.).
О кнопках:
case-insensitive– при установке флажка в окне система не различает заглавные и строчные буквы;
between ... and ...– между ... и... (окно указания временного периода, вводится год начала исследования и конца исследования);
from the corpus– из корпуса (выбрать из выпадающего меню)

with smoothing– со сглаживанием (выбрать из выпадающего меню);
search lots of books– искать в массивах книг (кнопка команды на поиск и построение графика).
Кроме построения графиков, система представляет ссылки к текстам, найденным по запросам. Как правило, это библиографические описания книг и фрагменты текстов с выделением в них цветом заданных N-грамм. В некоторых случаях доступен полный текст книги в графическом формате.
Запросы
Чтобы получить сравнить частотности нескольких единиц, запишите их через запятую.

По умолчанию поиск осуществляется с учетом регистра: если вы хотите это изменить, поставьте соответствующий флажок.
По умолчанию осуществляется поиск конкретных словоформ (какТочный поискв НКРЯ), если вы хотите искать все словоформы, припишите _INF в конце слова (например: птица_INF)

Если вместо одного из слов поставить астериск, то буду показаны 10 самых частотных биграмм со вторым словом:
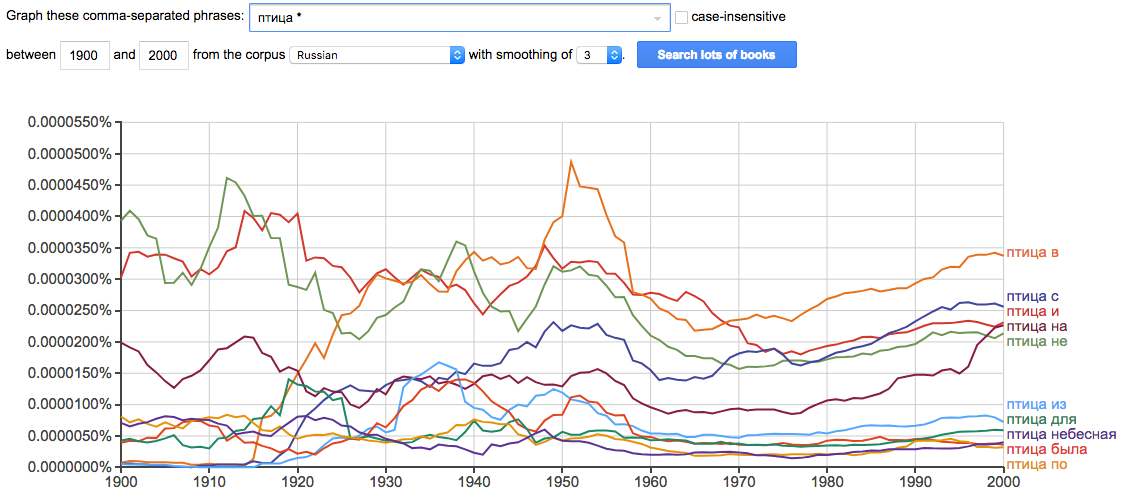
Искать можно не только конкретные слова, но их грамматические характеристики.
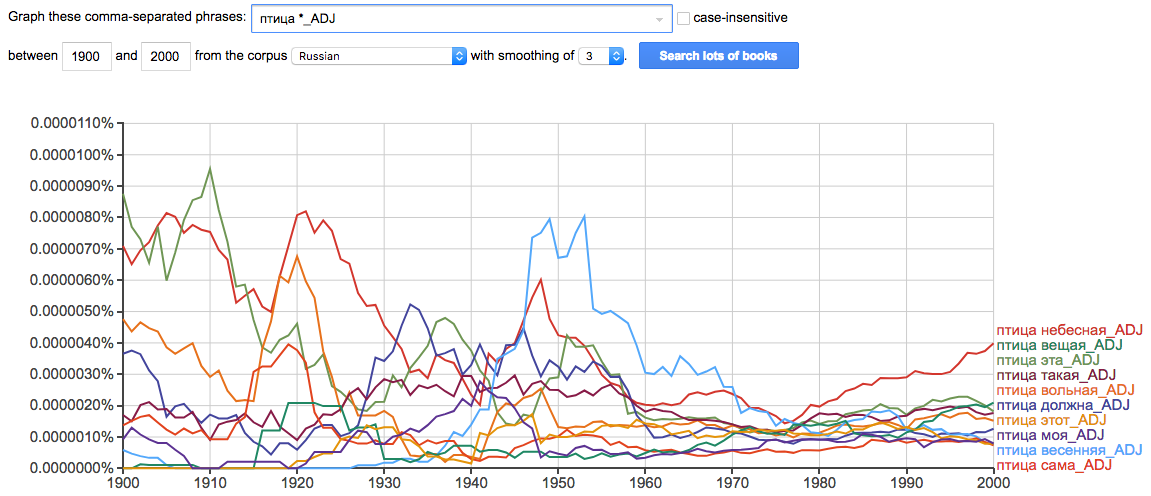

Cравнение Google NGrams и НКРЯ (данные за 2012 год)
| Характеристика | НКРЯ | Google books (rus_2012) |
|---|---|---|
| Объем корпуса (число документов) | 85 996 | 591 310 |
| Число словоупотреблений | 229 968 798 | 67 137 666 353 |
| Единицы частоты употребления N-грамм | IPM (Instances per million – число употреблений N-граммы на миллион словоупотреблений) | Проценты (число употреблений N-граммы на сто употреблений последовательностей той же длины) |
| Система письма | Большинство текстов основного корпуса частично представлены в современной системе письма, но некоторая часть текстов – в старой орфографии | Тексты представлены как в современной , так и в старой системе письма. Однако при поиске текстов в старой системе письма имеются проблемы |
| Операции над графиками | невозможны | возможны |
| Возможности отбора материала | создание пользовательских подкорпусов по разным критериям | Отбор материала и построение графиков осуществляется только по году издания. |
Операции над графиками
Суммирование (сложение) графиков(стол+стола+столов)
Операция позволяет суммировать значения каждой точки двух или более графиков. Для осуществления операции поисковые слова вводятся в окно через знак +, например: лошадь + лошади +лошадей.
Вычитание графиков(перст-палец)
Операция позволяет вычитать из значения каждой точки графика, значение той же по горизонтали точки другого графика. С помощью этой операции можно представить, насколько частота встречаемости одной N-граммы больше (меньше) другой, и как это различие менялось во времени. Для осуществления операции поисковые слова вводятся в окно через знак «-», например,вежливость-корректность. Все выражение следует взять в круглые скобки: (вежливость-корректность). При этой операции вся кривая или её часть может находиться в области отрицательных значений.
Умножение графиков(марксизм*100), марксизм
Операция позволяет умножать наnзначения всех точек графика. Операция умножения позволяет сделать сопоставимым поведение кривых, значения которых отличаются на несколько порядков. Слова в поисковое окно вводятся следующим образом: слово знак «*» множитель, например, лемматизация*100.
Деление графиков(сапоги/валенки),сапоги,валенки
Делить значение каждой точки графика на значение точки другого графика, имеющий ту же координату горизонтальной оси. Операция позволяет установить, во сколько раз один термин встречается чаще другого.Слова в поисковое окно вводятся следующим образом: слово – делимое, знак «/», слово – делитель, например сапоги/валенки.
Примечание. Операцию деления нельзя использовать по тому же типу, что операцию умножения. Выражение Время/100 означает, что система покажет, во сколько раз в текстах БД слово «время» встречается чаще (реже) чем цифра 100, а не уменьшит результат в сто раз. Это делает невозможной операцию вычисления средней встречаемости нескольких терминов.
SketchEngine
SketchEngine– система, позволяющая изучать сочетаемость слов на основе корпусов разных языков, причем не просто по соседству в тексте, а по грамматическим отношениям.
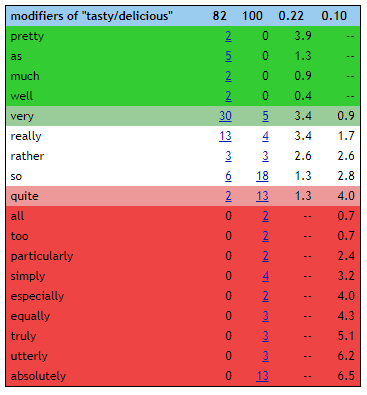

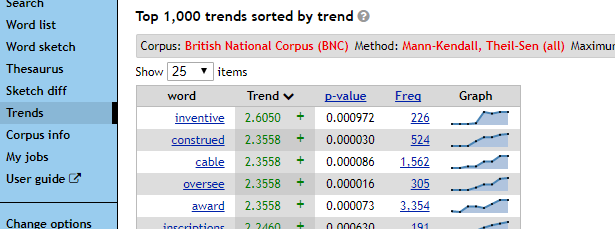
AntConc
С помощью данной программы можно производить поиск и подсчет различных элементов текста, анализировать частотность и контекст употребления словоформ, словосочетаний и морфем, сравнивать употребительность словоформ в разных текстах.
Отсутствие морфологического анализатора частично компенсируется возможностью подключения пользовательского списка лемм. Программа может быть использована для получения привязанных к заданной предметной области словарных минимумов, списков устойчивых сочетаний (в том числе терминологических), выборок к тематическим группам слов.
Проще говоря, это программа, которая позволяет создать собственный корпус. Чтобы загрузить файл в менюFileнажимаем «Open File» (файл должен быть в формате .txt/.xml/.html).
1.Открываем во второй сверху строке меню кнопку «Word List» (вторяя слева) и нажимаем кнопку «Start» (внизу ближе к левому краю). Программа выстроит все словоформы текста в порядке частотности
2.Можно сортировать и по другим критериям. Если вместо «Sort by Freq» (в самом низу) выбрать «Sort by Word», произойдет сортировка по алфавиту, если выбрать «Sort by Word End», сортировка пойдет по концу слов.
3.Если к тому же поставим галочку между фразами «Sort by» и «Invert Order», то сортировка пойдет в обратном порядке — от редких слов к частым или отядоа.
4.Можно кликнуть из списка любое слово, начнется его автоматический поиск в окнеConcordance.
Конкорданс– это список всех употреблений заданного языкового выражения (например, слова) в контексте, возможно, со ссылками на источник.
(В НКРЯ нечто похожее было тогда, когда мы выводили в KWIC.)
Если открыто окноConcordance, искомое слово можно ввести в окошко, находящееся между кнопкой «Start» и фразой «Search Term» и нажать «Start». Будет происходить поиск данного слова в контекстах.
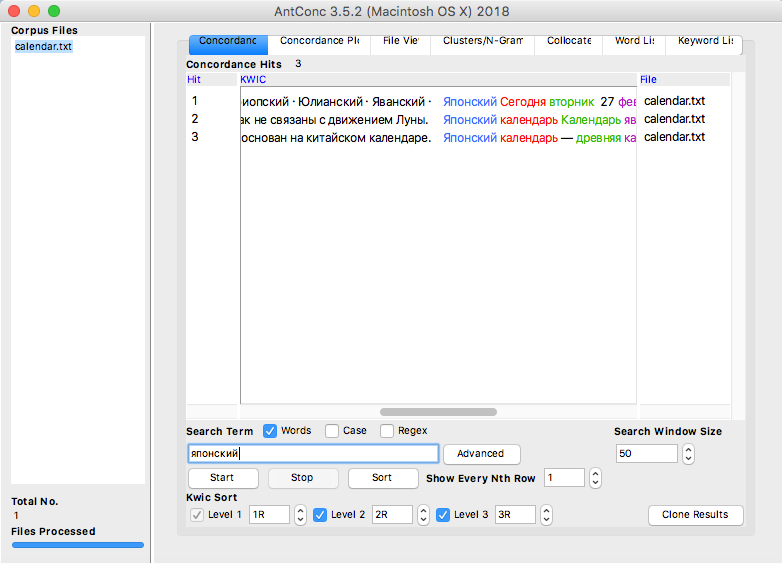
Если убрать галочку над тем же окошком между словами «Search Term» и «Words», можно будет искать не только конкретную форму слова, но и похожие формы: например, пишем пункт — выйдет пункта, пункты и т. п.
Кроме того можно использовать следующие специальные символы:
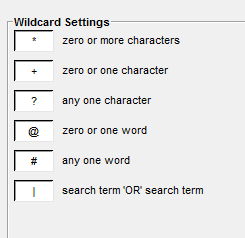
Вы можете сохранить результаты вашего поиска в отдельный файл: во вкладкеFile–> «Save Output».
График конкорданса (Concordance Plot).В этом инструменте все адреса для каждого элемента поиска представлены в виде «штрих-кода», указывающего на место в файле, где находится элемент. График позволяет увидеть, какие файлы включают искомый элемент. Он также может быть использован для определения места, где сталкиваются искомый элемент и кластер. Во вкладкеFile Viewвы можете посмотреть расширенный контекст, в котором встречается искомое слово.

Кластеры (Clusters).Инструменткластерыиспользуется для создания упорядоченного списка кластеров, которые появляются вокруг поиска в целевом файле, перечисленные в левой части главного окна. С помощью функцииCluster Sizeмы можем изменять длину искомой последовательности.Search Term Positionзадаёт позицию искомого слова внутри N-граммы.
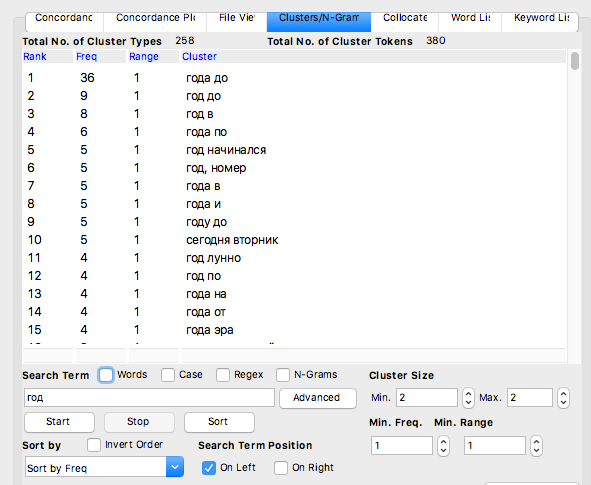
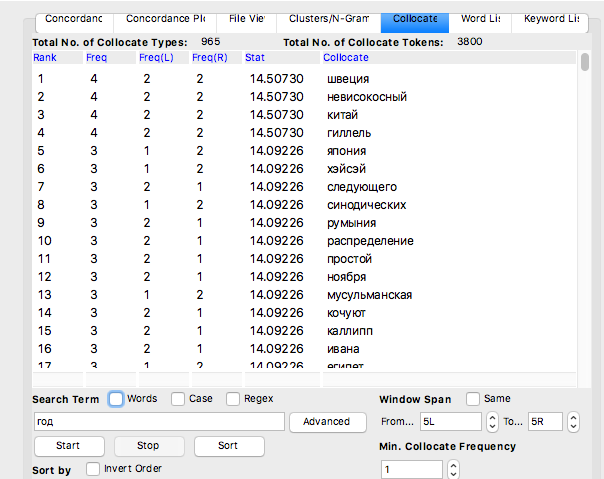
Коллокации (Collocates). Кластеры показывают N-граммы, которые встречаются в тексте (т.е. слова, которые стоят рядом друг с другом непосредственно), тогда как в списке коллокаций мы видим слова, которые статистически часто встречаются с искомым словом (слова, находящиеся в «окне поиска» –Window Span).
Freq(R) насколько часто встречается данное слово справа от искомого
Freq(L) насколько часто встречается данное слово слева от искомого
Freq насколько часто встречается данное слово вместе с искомым
Stat вероятность того, что данные слова встретятся вместе относительно того насколько часто они встречаются по отдельности.
Список слов.Данный инструмент подсчитывает все слова в корпусе и представляет их в упорядоченном списке. Это позволяет быстро найти, какие слова употребляются наиболее часто в корпусе.
Список ключевых слов.В дополнение к созданию списка слов, с помощьюAntConcможно сравнить слова в целевом файле со словами, которые появляются в «базисном корпусе», чтобы создать список "Ключевых слов", которые являются наиболее частыми (или редкими) в целевых файлах.
Полезные ссылки
Advanced Usage of Google NGram Viewer
Corpus Analysis with AntConc(tutorial)