Регулярные выражения
Регулярные выражения (regular expressions, RegExp) - это формальный язык для операций (поиск, замена и т.п.) с подстроками в тексте. Иными словами, это способ задать некоторый паттерн и найти / заменить на что-либо те кусочки текста, которые с ним совпадают. С регулярными выражениями можно работать в таких текстовых редакторах, как Notepad++, Sublime, Geany и др. или на следующих сайтах:
При работе с сайтом вы увидите не только совпадения, но и разбор вашего регулярного выражения.

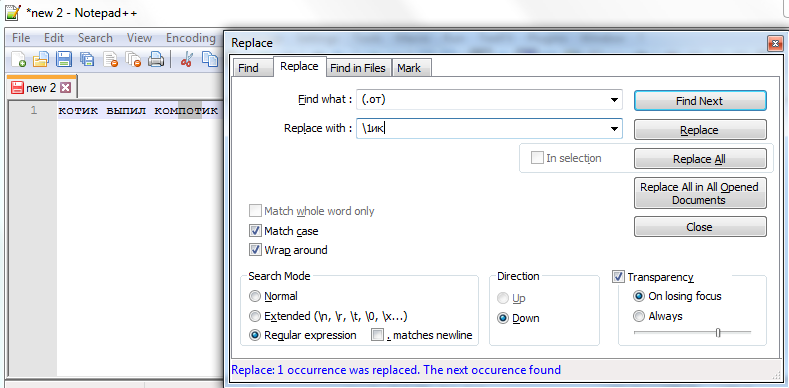
А вот так выглядит работа с регулярными выражениями в Notepad++ (чтобы попасть в это меню, нужно нажать Ctrl+F или Поиск) и выставить нужные флажки (обязательно - регулярные выражения, если необходимо - чувствительность к регистру, направление поиска, учет переноса строки).

Команда "Find all":

Команда "Replace all" (все подстроки, совпадающие с паттерном ".от", заменяются на то же самое + "ик", т.е. из "кот выпил компот" получается "котик выпил компотик").
Выбор и группировка символов
- . - любой символ
- | - или все то, что слева, или то, что справа
- () - группировка символов (если сомневаетесь, ставить их или нет, то лучше поставить :)
Часть регулярки, заключенная в скобки, называется группой. Группы нумеруются по открывающей скобке.

- \1 - группа с соответствующим номером (используется при замене)
- [ ] - любой единичный символ из заключенных в скобки
- [^ ] - любой единичный символ кроме заключенных в скобки
NB! Внутри [ ] не работают операторы . * + и т.д.
Количественные операторы (квантификаторы)
- ? - предыдущий символ/группа может быть, а может не быть
- + - предыдущий символ/группа может повторяться 1 и более раз
- * - предыдущий символ/группа может повторяться 0 и более раз
- {n,m} - предыдущий символ/группа может повторяться от от n до m включительно
- {n,} - предыдущий символ/группа в скобках может повторяться n и более раз
- {,m} - предыдущий символ/группа может повторяться до m раз
- {n} - предыдущий символ/группа повторяется n раз
Классы (диапазоны) символов
- [A-Z] - один любой символ верхнего регистра (латиница)
- [a-z] - любой символ нижнего регистра (латиница)
- [А-Я] - любой символ верхнего регистра (кириллица)
- [а-я] - любой символ нижнего регистра (кириллица)
- [0-9] или \d - цифра
- [^0-9] или \D - любой символ, кроме цифры
Можно комбинировать:
- [A-Za-z] - любой символ верхнего и нижнего регистра (латиница)
- [A-Za-z0-9] - любой символ верхнего и нижнего регистра (латиница) и цифры
- [A-Za-z0-9_] или \w - любой символ верхнего и нижнего регистра (латиница), цифры и _
- [^A-Za-z0-9_] или \W - все, кроме символов верхнего и нижнего регистра (латиница), цифр и _
Служебные символы:
- \t - табуляция
- \s - любой пробельный символ
- \S - все, кроме пробелов
- \n (или \r\n на Windows) - перенос строки
- ^ - начало строки
- $ - конец строки
"Жадные" и "ленивые" операторы
Квантификаторы по умолчанию ведут себя жадно: это значит, что они стремятся "съесть" как можно больше символов и из всех возможных вариантов они поймают наиболее длинную строку. Например, мы хотим найти в строке кот выпил компот слова "кот" и "компот" и пишем такое выражение: к.*от (читается как "к, любой символ в количестве от 0 до бесконечности, от"), где .* - любое количество любых символов. Однако такое выражение выдаст даст следующий результат:
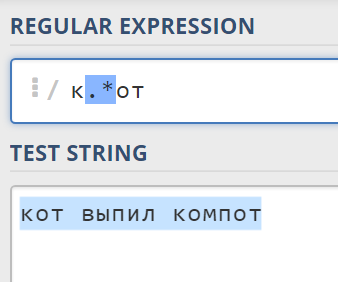
Максимальное количество символов между "к" и "от" в этой строке - 13, "от выпил компо", и наш жадный оператор поймал именно его. Чтобы найти более короткие совпадения, т.е. отдельно "кот" и "компот", нужно превратить жадный оператор в ленивый, поставив после него знак "?". Это работает со всеми квантификаторами.

| Жадные квантификаторы | Ленивые квантификаторы |
|---|---|
| * | *? |
| + | +? |
| ? | ?? |
| {min, max} | {min, max}? |
Экранирование служебных символов
Вы уже заметили, что как и любой язык, регулярные выражения записываются с помощью особого алфавита - точек, звездочек, скобочек и т.д. Но что делать, если нужно найти служебные символы вроде + или * в тексте? Все просто: нужно экранировать их, т.е. поставить перед ними \. В этом примере мы экранируем *, чтобы сделать ее из служебного символа текстовым, а вот + так и остался служебным и означает "один и более раз".

Найди Кьеркегора!
Датский философ Søren Kierkegaard известен не только своими работами, но и количеством вариантов написания фамилии на русском языке. Вот пример регулярного выражения, которое найдет всех Кьеркегоров в тексте и не зацепит ничего лишнего:
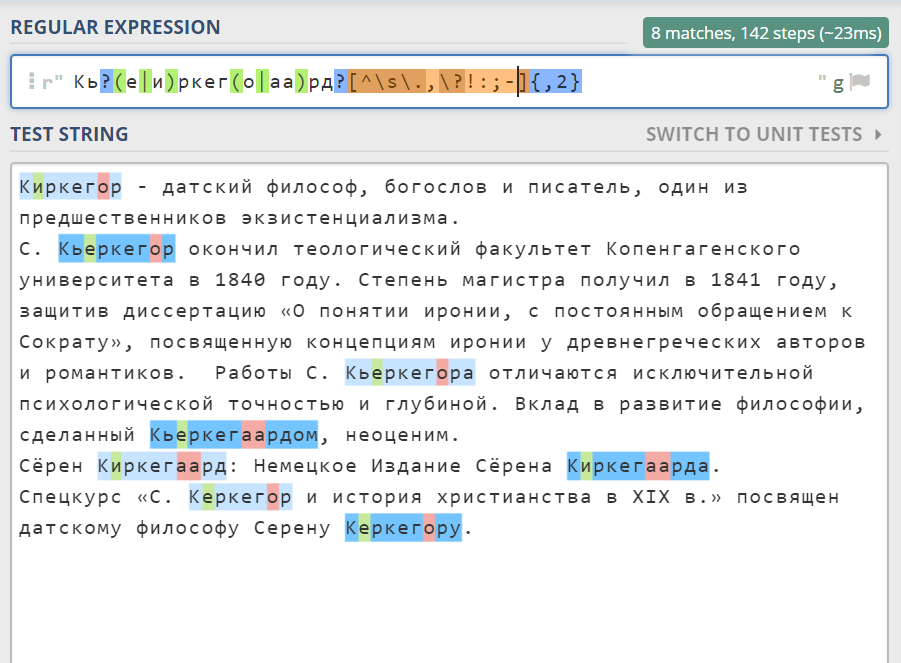
- К - соответствует заглавной букве "К" (строчную "к" ловить не будет)
- ь? - мягкий знак может быть, а может не быть
- (е|и) - дальше может быть либо "е", либо "и"; если скобочки не поставить, то выбор будет не только между двумя буквами, а между все строкой до | и всей строкой после |.
- ркег - просто ищет соответствующую последовательность
- (о|аа) - дальше может быть либо "о", либо "аа
- р - просто "р"
- д? - "д" может быть, а может не быть
- [^\s.,\?!:;-] - дальше может идти любой знак кроме пробела и знаков пунктуации (это нужно, чтобы поймать Кьеркегора во всех падежах)
- {,2} - предыдущее выражение может встречаться от 0 (И.п. "Кьеркегор") до 2 (Т.п. "Кьеркегором") раз
Конечно же, это громоздкое выражение можно упростить -- подумайте сами, как это сделать. А заодно запомните золотое правило регулярок: чем проще, тем лучше. :)