Работа с Национальным корпусом русского языка (НКРЯ)
Национальный корпус русского языка-- это большаяколлекция текстов разных веков и жанров с морфологической разметкой и поисковым интерфейсом.
НКРЯ представляет русский язык в наиболее полном виде: во всём многообразии жанров, стилей, территориальных и социальных вариантов и содержит все типы письменных и устных текстов, представленных в русском языке. В Корпусе собраны художественные тексты разных жанров от Фонвизина до Улицкой, поэзия с конца 18 века, публицистика XX-XXI веков (особенно широко представлена публицистика последних 40 лет), научная литература всех направлений (точные, естественные и гуманитарные науки), официально-деловые тексты: заявления, служебные записки, инструкции, тексты бытовых жанров: мемуары, дневниковые записи, личная переписка, фрагменты интернет-чатов, записи устной разговорной речи, а также записи устной речи из фильмов, диалектные тексты и др.[studiorum]
Чтобы лучше оценить объемы и многообразие данных в НКРЯ, можно посмотретьстатистику.
Тексты размечены по следующимпараметрам:
А чтобы было проще в них ориентироваться, НКРЯ разбит на подкорпуса:
- основной
- синтаксический
- газетный
- параллельный
- обучающий
- диалектный
- поэтический
- устный
- акцентологический
- мультимедийный
- мультипарк
- исторический
Историческийкорпус содержит тексты на древнерусском языке, всинтаксическом корпусепомимо морфологических характеристик слов указаны их синтаксические связи в предложении, впоэтическомимеется особая разметка для строфики и рифмы, апараллельный корпуспредставляет собой собрание одинаковых текстов на каких-либо двух языках (русский и французский, русский и китайский, русский и бурятский и т.п.)
У НКРЯ естьсобственный образовательный портал, на котором вы найдетемануал по работе с корпусомс пошаговыми инструкциями и скриншотами по разным видам поиска (слово, словосочетание, слово с определенными грамматическими характеристиками...) и созданию собственных подкорпусов (это нужно, чтобы ограничить набор текстов, в которых вы будете искать какое-то слово, по годам или по жанрам, например) .
Поисковая выдача выглядит вот так: списком даются тексты (они называютсядокументами) и примеры с ключевым словом, найденные в них.
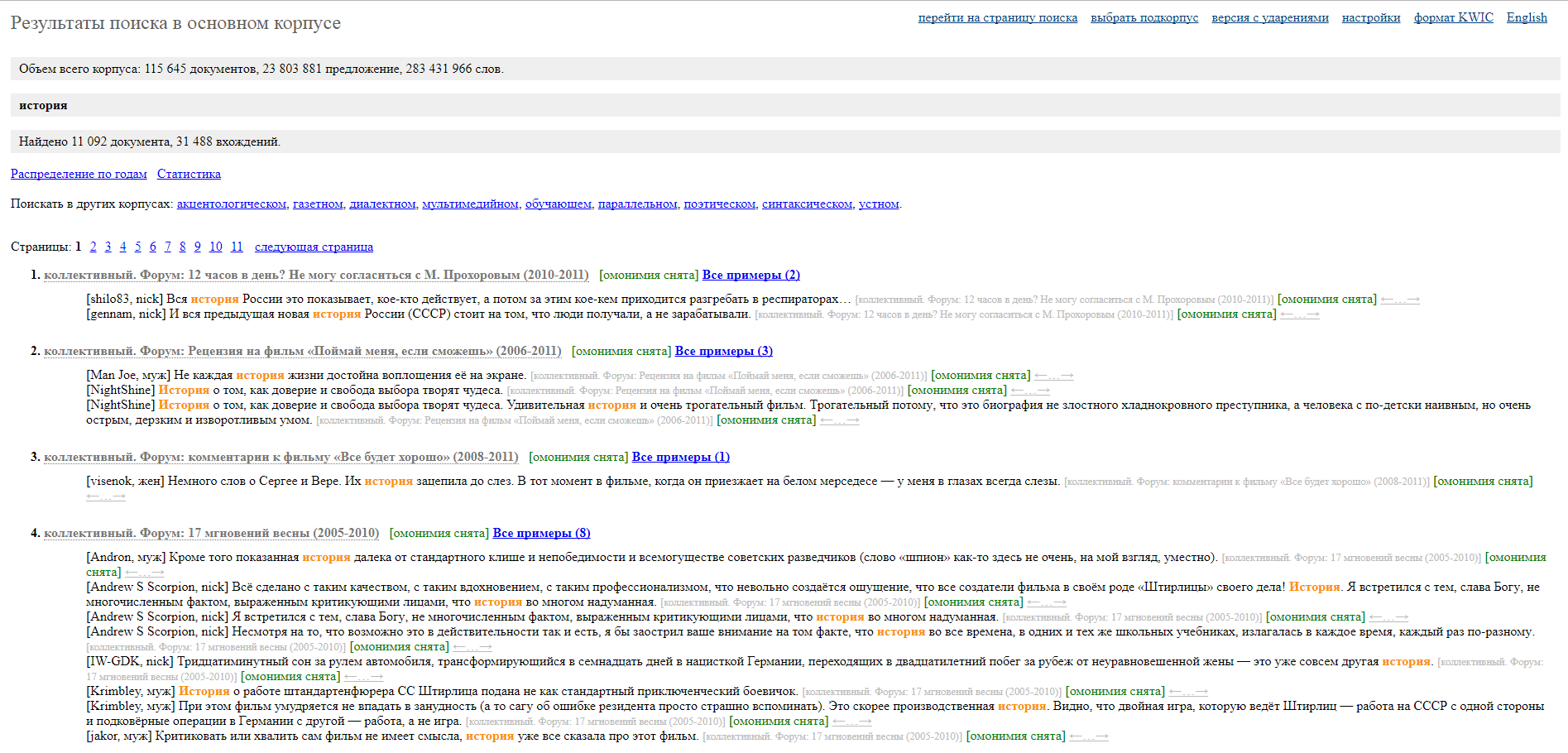
Также в скобках указано, снятаомонимияили нет: если да, то у слова будет один грамматический разбор, выбранный разметчиком, а если нет, значит вы увидите несколько возможных разборов, сгенерированных машиной. Чтобы посмотреть грамматические характеристики слова, нужно просто нажать на него: во всплывающем окне будет указана еголемма(она же словарная форма), грамматический разбор и семантический класс.
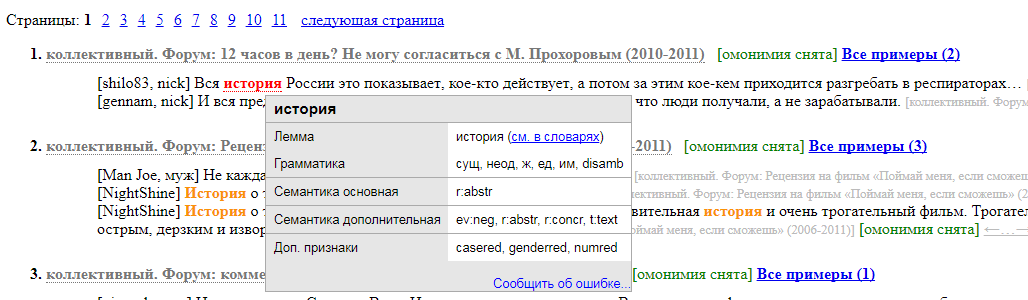
Грамматический разбор состоит из нескольких элементов, которые называютсяграммемами, илиграмматическими тегамии могут принимать разные значения: например, часть речи (существительное, глагол, прилагательное...), число (единственное, множественное), падеж (именительный, родительный...). Со списком обозначений граммем и их расшифровками можно ознакомиться настранице с описанием морфологической разметки. Синтаксическую разметку, в свою очередь, можно посмотретьвот тут, а семантическую --тут.

Помимо стандартной выдачи можно посмотреть результаты в форматеKWIC(Key Word In Context),в котором отображается правый и левыйконтекстключевого слова. Все примеры выравниваются по ключевому слову, поэтому выдачу в таком формате очень удобно анализировать.
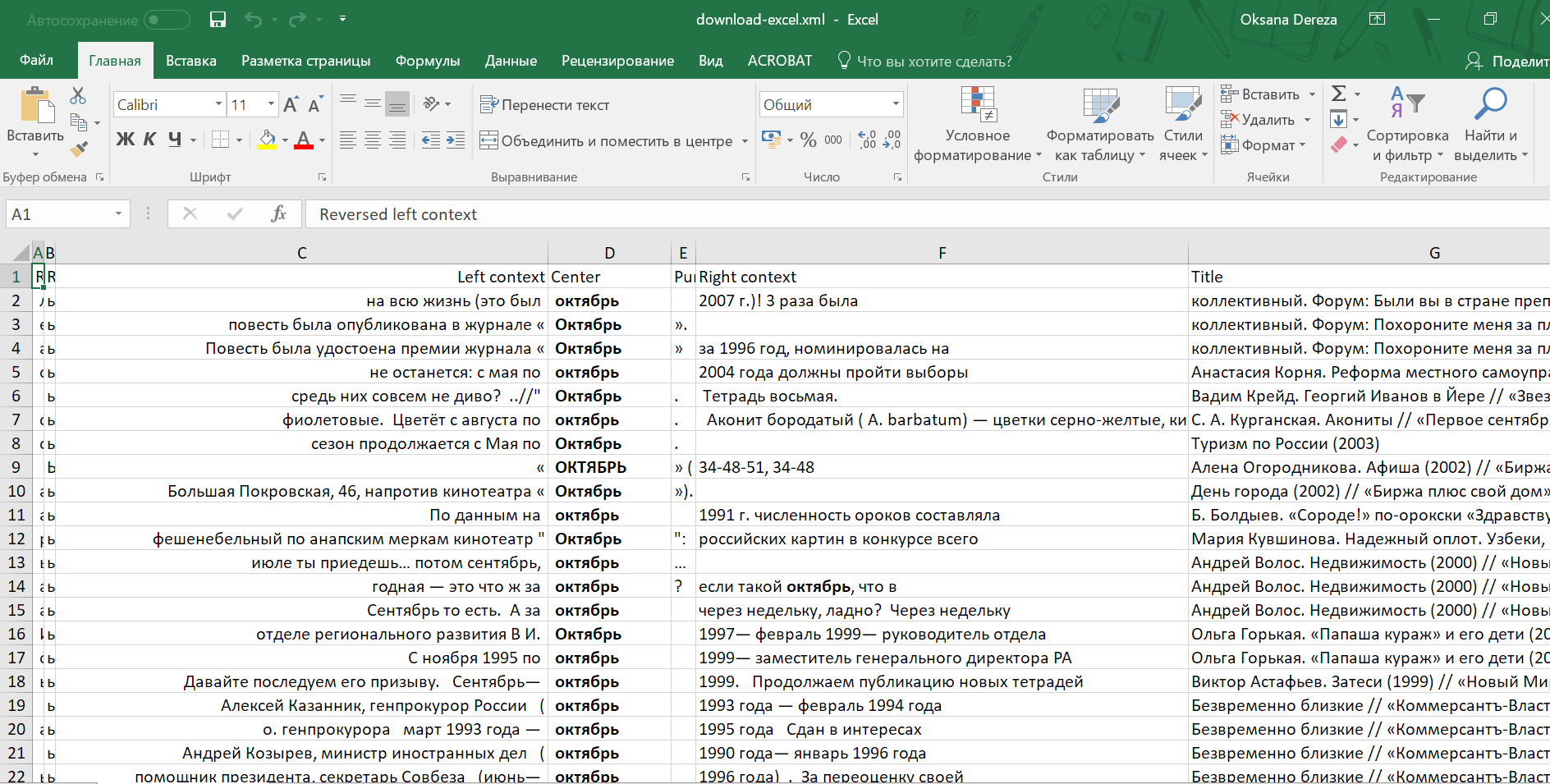
Небольшую выборку из результатов поиска можно скачать либо в стандартном форматеXML(в котором, кстати, хранятся все тексты корпуса), либо в специальном XML, адаптированном под табличные процессоры Excel и Open Office. Панель скачивания результатов выдачи расположена в самом низу страницы.

Открыв такой файл, вы увидите результаты поиска в формате KWIC, разбитые по колонкам "левый контекст", "центральное слово", "пунктуация", "правый контекст", "источник текста". Если вы хотите поближе познакомиться с XML-разметкой, можно почитатьвот этот мануалот Microsoft.
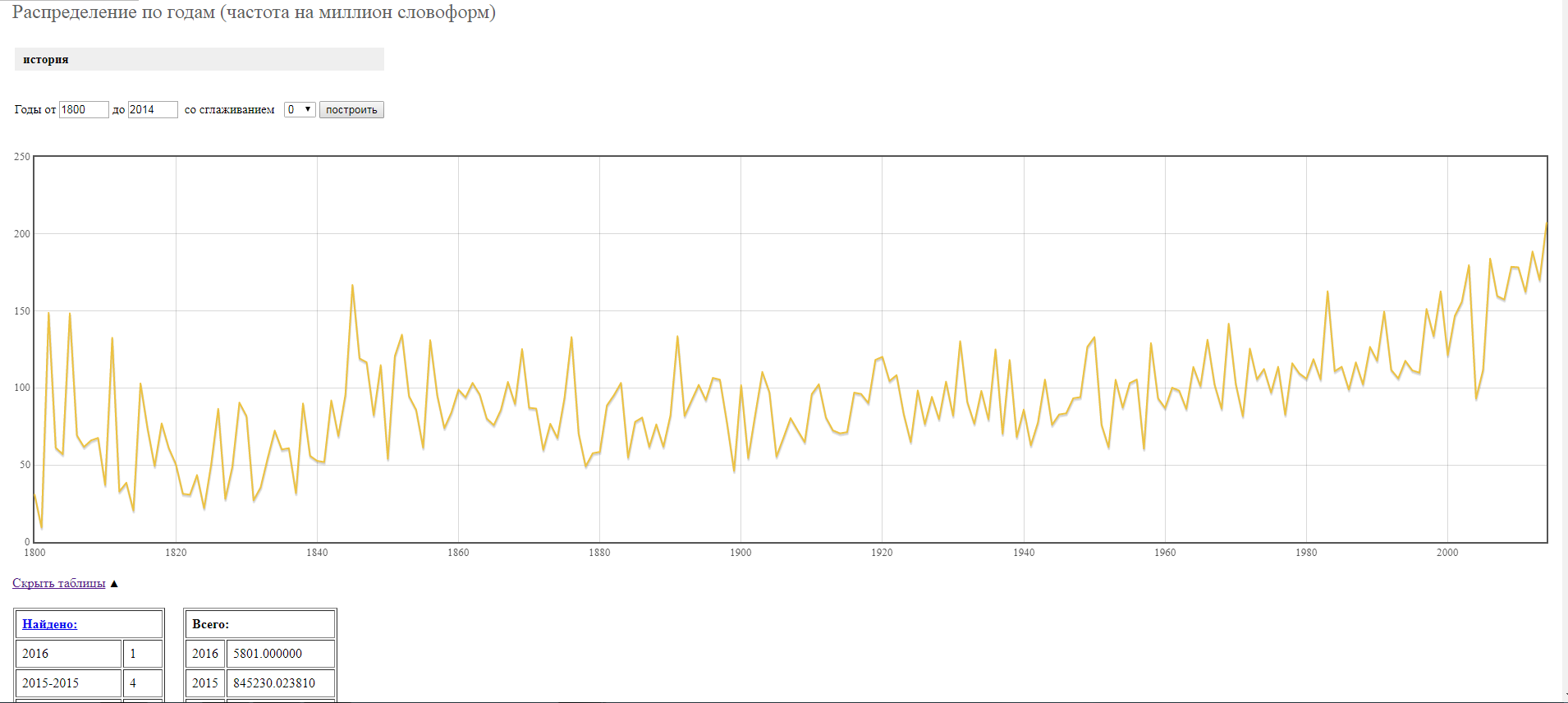
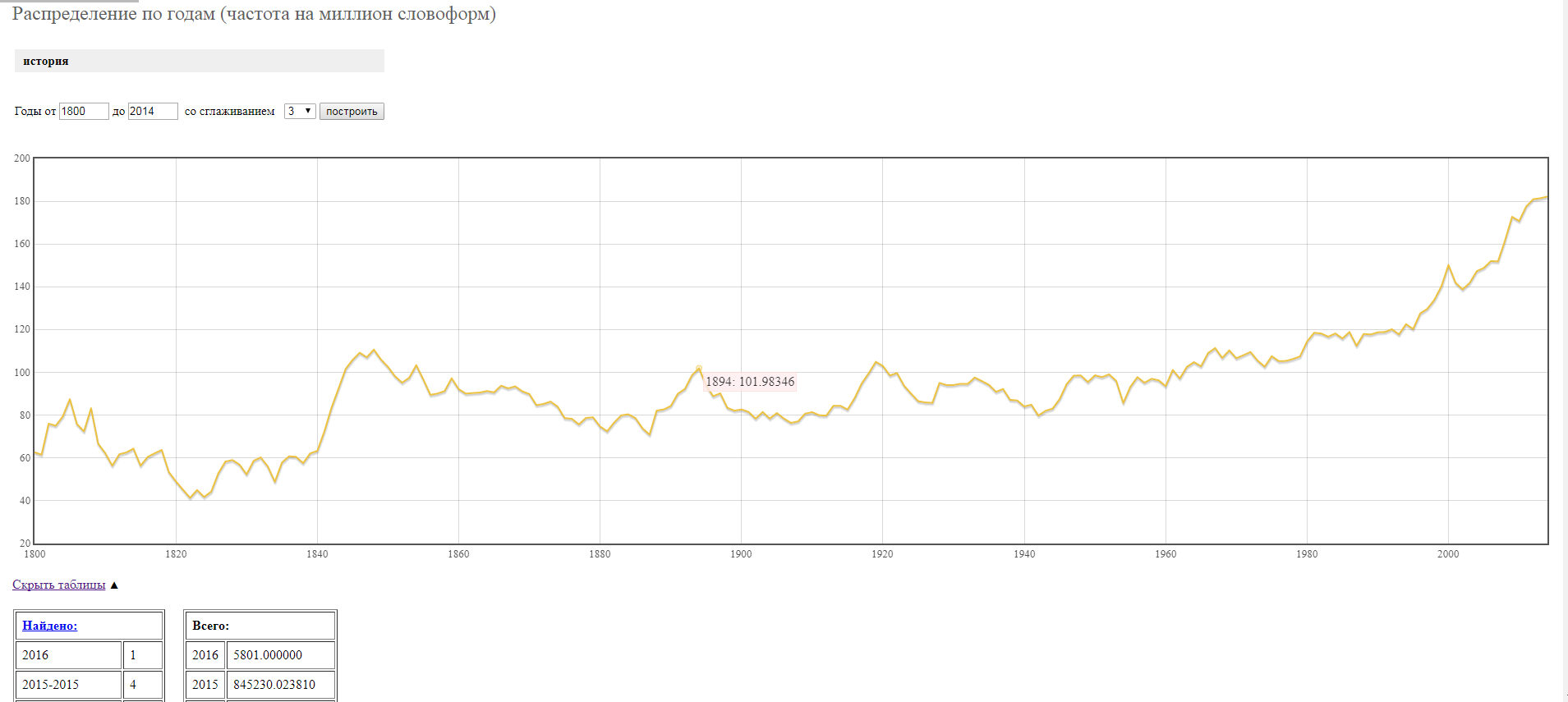
Кроме того, НКРЯ умеет смотреть статистику употребления слова по годам и строить по ней графики. Если навести курсор на график, можно увидеть значениеipm(items per million), илиотносительную частоту употребленияза определенный год для данного слова. Частота ipm определяется как количество употреблений слова за год, поделенное на объем корпуса за этот год и умноженное на 1 миллион. Под графиком приведенытаблицы с абсолютным количествомупотреблений за определенный период времени. Перейти к графику можно либо по ссылке "Посмотреть статистику" на странице выдачи, либовот здесь.
Чем меньше значение сглаживания, тем более ломаной будет линия на графике. Ниже приведены графики, построенные по одним и тем же данным со сглаживанием 0 и 20.